|
FastFlow
SVN-r182-Aug-14-2014
A high-level, lock-less, parallel programming (shared-memory) and distributed programming (distributed-memory) framework for multi-cores and many-cores systems
|
|
FastFlow
SVN-r182-Aug-14-2014
A high-level, lock-less, parallel programming (shared-memory) and distributed programming (distributed-memory) framework for multi-cores and many-cores systems
|
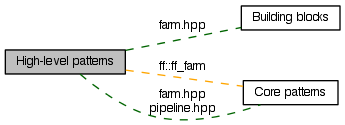
Patterns for "in-place" (easy) parallelisation of sequential code. More...
 Collaboration diagram for High-level patterns:
Collaboration diagram for High-level patterns:Files | |
| file | farm.hpp |
| Farm pattern. | |
| file | map.hpp |
| map pattern | |
| file | mdf.hpp |
| This file implements the macro dataflow pattern. | |
| file | parallel_for.hpp |
| This file describes the parallel_for/parallel_reduce skeletons. | |
| file | pipeline.hpp |
| This file implements the pipeline skeleton, both in the high-level pattern syntax (ff::ff_pipe) and low-level syntax (ff::ff_pipeline) | |
| file | poolEvolution.hpp |
| The PoolEvolution pattern models the evolution of a given population. | |
Classes | |
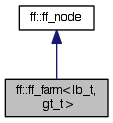
| class | ff::ff_farm< lb_t, gt_t > |
The Farm skeleton, with Emitter (lb_t) and Collector (gt_t). More... | |
| class | Map |
| Map pattern. More... | |
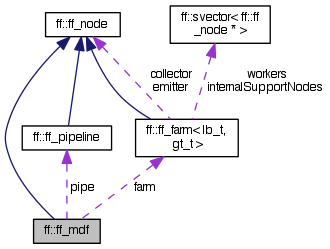
| class | ff::ff_mdf |
| Macro Data Flow executor. More... | |
| class | ff::ParallelFor |
| Parallel for loop. Run automatically. More... | |
| class | ff::ParallelForReduce< T > |
| Parallel for and reduce. Run automatically. More... | |
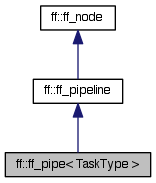
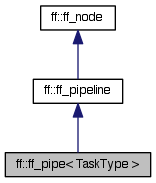
| class | ff::ff_pipe< TaskType > |
| Pipeline pattern (high-level pattern syntax) More... | |
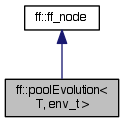
| class | ff::poolEvolution< T, env_t > |
| The pool evolution parallel pattern. More... | |
Functions | |
| template<typename T > | |
| ff::ff_farm< lb_t, gt_t >::ff_farm (const std::function< T *(T *, ff_node *const)> &F, int nw, bool input_ch=false) | |
| High-level pattern constructor. | |
Patterns for "in-place" (easy) parallelisation of sequential code.
They are clearly characterised in a specific usage context and are targeted to the parallelisation of sequential (legacy) code. Examples are exploitation of loop parallelism, stream parallelism, data-parallel algorithms, execution of general workflows of tasks, etc. The are typically equipped with self-optimisation capabilities (e.g. load-balancing, grain auto-tuning, parallelism-degree auto-tuning) and exhibit no or limited nesting capability. Examples are: parallel-for, pipeline, stencil-reduce, mdf (macro-data-flow). Some of them targets specific devices (e.g. GPGPUs). They are implemented on top of core patterns.
| class ff::ff_farm |
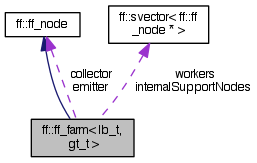
The Farm skeleton, with Emitter (lb_t) and Collector (gt_t).
The Farm skeleton can be seen as a 3-stages pipeline. The first stage is the Emitter (lb_t) that act as a load-balancer; the last (optional) stage would be the Collector (gt_t) that gathers the results computed by the Workers, which are ff_nodes.
This class is defined in farm.hpp
Inheritance diagram for ff::ff_farm< lb_t, gt_t >: Collaboration diagram for ff::ff_farm< lb_t, gt_t >:Public Member Functions | |
| template<typename T > | |
| ff_farm (const std::function< T *(T *, ff_node *const)> &F, int nw, bool input_ch=false) | |
| High-level pattern constructor. | |
| ff_farm (std::vector< ff_node * > &W, ff_node *const Emitter=NULL, ff_node *const Collector=NULL, bool input_ch=false) | |
| Core patterns constructor 2. More... | |
| ff_farm (bool input_ch=false, int in_buffer_entries=DEF_IN_BUFF_ENTRIES, int out_buffer_entries=DEF_OUT_BUFF_ENTRIES, bool worker_cleanup=false, int max_num_workers=DEF_MAX_NUM_WORKERS, bool fixedsize=false) | |
| Core patterns constructor 1. More... | |
| ~ff_farm () | |
| Destructor. More... | |
| int | add_emitter (ff_node *e) |
| Adds the emitter. More... | |
| void | set_scheduling_ondemand (const int inbufferentries=1) |
| Set scheduling with on demand polity. More... | |
| int | add_workers (std::vector< ff_node * > &w) |
| Adds workers to the form. More... | |
| int | add_collector (ff_node *c, bool outpresent=false) |
| Adds the collector. More... | |
| int | wrap_around (bool multi_input=false) |
| Sets the feedback channel from the collector to the emitter. More... | |
| int | remove_collector () |
| Removes the collector. More... | |
| int | run (bool skip_init=false) |
| Execute the Farm. More... | |
| virtual int | run_and_wait_end () |
| Executs the farm and wait for workers to complete. More... | |
| virtual int | run_then_freeze (ssize_t nw=-1) |
| Executes the farm and then freeze. More... | |
| int | wait () |
| Puts the thread in waiting state. More... | |
| int | wait_freezing () |
| Waits for freezing. More... | |
| bool | offload (void *task, unsigned int retry=((unsigned int)-1), unsigned int ticks=ff_loadbalancer::TICKS2WAIT) |
| bool | load_result (void **task, unsigned int retry=((unsigned int)-1), unsigned int ticks=ff_gatherer::TICKS2WAIT) |
| Loads results into gatherer. More... | |
| bool | load_result_nb (void **task) |
| Loads result with non-blocking. More... | |
| double | ffTime () |
| Misure ff::ff_node execution time. More... | |
| Public Member Functions inherited from ff::ff_node | |
| virtual bool | put (void *ptr) |
| Nonblocking put onto output channel. More... | |
| virtual bool | get (void **ptr) |
| Noblocking pop from input channel. More... | |
| virtual FFBUFFER * | get_in_buffer () const |
| Gets input channel. More... | |
| virtual FFBUFFER * | get_out_buffer () const |
| Gets pointer to the output channel. More... | |
| virtual bool | ff_send_out (void *task, unsigned int retry=((unsigned int)-1), unsigned int ticks=(TICKS2WAIT)) |
| Sends out the task. More... | |
Protected Member Functions | |
| void | skipfirstpop (bool sk) |
| Set the ff_node to start with no input task. More... | |
| void * | svc (void *task) |
| svc method | |
| int | svc_init () |
| The svc_init method. | |
| void | svc_end () |
| The svc_end method. | |
| int | create_input_buffer (int nentries, bool fixedsize) |
| Creates the input buffer for the emitter node. More... | |
| int | create_output_buffer (int nentries, bool fixedsize=false) |
| Creates the output channel. More... | |
| int | set_output_buffer (FFBUFFER *const o) |
| Sets the output buffer of the collector. More... | |
| ff_node * | getEmitter () |
| Gets Emitter. More... | |
| ff_node * | getCollector () |
| Gets Collector. More... | |
| Protected Member Functions inherited from ff::ff_node | |
| bool | skipfirstpop () const |
| Gets the status of spontaneous start. More... | |
| virtual int | set_input_buffer (FFBUFFER *const i) |
| Assign the input channelname to a channel. More... | |
| virtual double | wffTime () |
| Misure ff_node::svc execution time. More... | |
| virtual | ~ff_node () |
| Destructor. | |
|
inline |
Destructor.
Destruct the load balancer, the gatherer, all the workers
|
inline |
Adds the collector.
It adds the Collector filter to the farm skeleton. If no object is passed as a colelctor, than a default collector will be added (i.e. ff_gatherer). Note that it is not possible to add more than one collector.
| c | Collector object |
| outpresent | outstream? |
set_filter(x) if successful, otherwise -1 is returned.
|
inline |
|
inline |
Adds workers to the form.
Add workers to the Farm. There is a limit to the number of workers that can be added to a Farm. This limit is set by default to 64. This limit can be augmented by passing the desired limit as the fifth parameter of the ff_farm constructor.
| w | a vector of ff_nodes which are Workers to be attached to the Farm. |
|
inlineprotectedvirtual |
Creates the input buffer for the emitter node.
This function redefines the ff_node's virtual method of the same name. It creates an input buffer for the Emitter node.
| nentries | the size of the buffer |
| fixedsize | flag to decide whether the buffer is resizable. |
Reimplemented from ff::ff_node.
|
inlineprotectedvirtual |
Creates the output channel.
| nentries | the number of elements of the buffer |
| fixedsize | flag to decide whether the buffer is bound or unbound. Default is true. |
Reimplemented from ff::ff_node.
|
inlinevirtual |
|
inlineprotected |
Gets Collector.
It returns a pointer to the collector.
NULL
|
inlineprotected |
Gets Emitter.
It returns a pointer to the emitter.
|
inline |
Loads results into gatherer.
It loads the results from the gatherer (if any).
| task | is a void pointer |
| retry | is the number of tries to load the results |
| ticks | is the number of ticks to wait |
false if EOS arrived or too many retries, true if there is a new value
|
inline |
Loads result with non-blocking.
It loads the result with non-blocking situation.
| task | is a void pointer |
FF_EOS
|
inline |
Offloads teh task to farm
It offloads the given task to the farm.
| task | is a void pointer |
| retry | showing the number of tries to offload |
| ticks | is the number of ticks to wait |
true if successful, otherwise false
|
inline |
Removes the collector.
It allows not to start the collector thread, whereas all worker's output buffer will be created as if it were present.
|
inlinevirtual |
Execute the Farm.
It executes the form.
| skip_init | A booleon value showing if the initialization should be skipped |
Reimplemented from ff::ff_node.
|
inlinevirtual |
Executs the farm and wait for workers to complete.
It executes the farm and waits for all workers to complete their tasks.
|
inlinevirtual |
Executes the farm and then freeze.
It executs the form and then freezes the form. If workers are frozen, it is possible to wake up just a subset of them.
|
inlineprotectedvirtual |
Sets the output buffer of the collector.
This function redefines the ff_node's virtual method of the same name. Set the output buffer for the Collector.
| o | a buffer object, which can be of type SWSR_Ptr_Buffer or uSWSR_Ptr_Buffer |
Reimplemented from ff::ff_node.
|
inline |
Set scheduling with on demand polity.
The default scheduling policy is round-robin, When there is a great computational difference among tasks the round-robin scheduling policy could lead to load imbalance in worker's workload (expecially with short stream length). The on-demand scheduling policy can guarantee a near optimal load balancing in lots of cases. Alternatively it is always possible to define a complete application-level scheduling by redefining the ff_loadbalancer class.
| inbufferentries | sets the number of queue slot for one worker threads. |
|
inlineprotectedvirtual |
Set the ff_node to start with no input task.
Setting it to true let the ff_node execute the svc method spontaneusly before receiving a task on the input channel. skipfirstpop makes it possible to define a "producer" node that starts the network.
| sk | true start spontaneously (*task will be NULL) |
Reimplemented from ff::ff_node.
|
inlinevirtual |
Puts the thread in waiting state.
It puts the thread in waiting state.
Reimplemented from ff::ff_node.
|
inlinevirtual |
Waits for freezing.
It waits for thread to freeze.
Reimplemented from ff::ff_node.
|
inline |
Sets the feedback channel from the collector to the emitter.
This method allows to estabilish a feedback channel from the Collector to the Emitter. If the collector is present, than the collector output queue will be connected to the emitter input queue (feedback channel)
| class ff::ff_mdf |
Macro Data Flow executor.
Inheritance diagram for ff::ff_mdf: Collaboration diagram for ff::ff_mdf:Public Member Functions | |
| template<typename T1 > | |
| ff_mdf (void(*F)(T1 *const), T1 *const args, size_t outstandingTasks=DEFAULT_OUTSTANDING_TASKS, int maxnw=ff_realNumCores(), void(*schedRelaxF)(unsigned long)=NULL) | |
| Constructor. More... | |
| void * | svc (void *) |
| The service callback (should be filled by user with parallel activity business code) More... | |
| double | ffTime () |
| Misure ff::ff_node execution time. More... | |
| Public Member Functions inherited from ff::ff_node | |
| virtual int | svc_init () |
| Service initialisation. More... | |
| virtual void | svc_end () |
| Service finalisation. More... | |
| virtual bool | put (void *ptr) |
| Nonblocking put onto output channel. More... | |
| virtual bool | get (void **ptr) |
| Noblocking pop from input channel. More... | |
| virtual FFBUFFER * | get_in_buffer () const |
| Gets input channel. More... | |
| virtual FFBUFFER * | get_out_buffer () const |
| Gets pointer to the output channel. More... | |
| virtual bool | ff_send_out (void *task, unsigned int retry=((unsigned int)-1), unsigned int ticks=(TICKS2WAIT)) |
| Sends out the task. More... | |
Additional Inherited Members | |
| Protected Member Functions inherited from ff::ff_node | |
| virtual void | skipfirstpop (bool sk) |
| Set the ff_node to start with no input task. More... | |
| bool | skipfirstpop () const |
| Gets the status of spontaneous start. More... | |
| virtual int | create_input_buffer (int nentries, bool fixedsize=true) |
| Creates the input channel. More... | |
| virtual int | create_output_buffer (int nentries, bool fixedsize=false) |
| Creates the output channel. More... | |
| virtual int | set_output_buffer (FFBUFFER *const o) |
| Assign the output channelname to a channel. More... | |
| virtual int | set_input_buffer (FFBUFFER *const i) |
| Assign the input channelname to a channel. More... | |
| virtual int | run (bool=false) |
| Run the ff_node. More... | |
| virtual int | wait () |
| Wait ff_node termination. More... | |
| virtual int | wait_freezing () |
| Wait the freezing state. More... | |
| virtual double | wffTime () |
| Misure ff_node::svc execution time. More... | |
| virtual | ~ff_node () |
| Destructor. | |
|
inline |
Constructor.
| F | = is the user's function |
| args | = is the argument of the function F |
| maxnw | = is the maximum number of farm's workers that can be used |
| schedRelaxF | = is a function for managing busy-waiting in the farm scheduler |
References ff::ff_farm< lb_t, gt_t >::add_emitter(), ff::ff_pipeline::add_stage(), ff::ff_farm< lb_t, gt_t >::add_workers(), ff::ff_pipeline::run_then_freeze(), ff::ff_pipeline::wait_freezing(), and ff::ff_farm< lb_t, gt_t >::wrap_around().
|
inlinevirtual |
Misure ff::ff_node execution time.
Reimplemented from ff::ff_node.
References ff::ff_pipeline::ffTime().
|
inlinevirtual |
The service callback (should be filled by user with parallel activity business code)
| task | is a the input data stream item pointer (task) |
Implements ff::ff_node.
| class ff::ParallelFor |
Parallel for loop. Run automatically.
Identifies an iterative work-sharing construct that specifies a region (i.e. a Lambda function) in which the iterations of the associated loop should be executed in parallel.
Public Member Functions | |
| ParallelFor (const long maxnw=FF_AUTO, bool spinwait=false) | |
| Constructor. More... | |
| ~ParallelFor () | |
| Destructor. More... | |
| void | disableScheduler (bool onoff=true) |
| Disable active scheduler (i.e. Emitter thread) More... | |
| template<typename Function > | |
| void | parallel_for (long first, long last, const Function &f, const long nw=FF_AUTO) |
| Parallel for region (basic) - static. More... | |
| template<typename Function > | |
| void | parallel_for (long first, long last, long step, const Function &f, const long nw=FF_AUTO) |
| Parallel for region (step) - static. More... | |
| template<typename Function > | |
| void | parallel_for (long first, long last, long step, long grain, const Function &f, const long nw=FF_AUTO) |
| Parallel for region (step, grain) - dynamic. More... | |
| template<typename Function > | |
| void | parallel_for_thid (long first, long last, long step, long grain, const Function &f, const long nw=FF_AUTO) |
| Parallel for region with threadID (step, grain, thid) - dynamic. More... | |
| template<typename Function > | |
| void | parallel_for_idx (long first, long last, long step, long grain, const Function &f, const long nw=FF_AUTO) |
| Parallel for region with indexes ranges (step, grain, thid, idx) - dynamic - advanced usage. More... | |
| template<typename Function > | |
| void | parallel_for_static (long first, long last, long step, long grain, const Function &f, const long nw=FF_AUTO) |
| Parallel for region (step, grain) - static. More... | |
|
inline |
Constructor.
Set up a parallel for ParallelFor pattern run-time support (i.e. spawn workers threads) A single object can be used as many times as needed to run different parallel for pattern instances (different loop bodies). They cannot be nested nor recursive. Nonblocking policy is to be preferred in case of repeated call of the some of the parallel_for methods (e.g. within a strict outer loop). On the same ParallelFor object different parallel_for methods (e.g. parallel_for and parallel_for_thid, parallel_for_idx) can be called in sequence.
| maxnw | Maximum number of worker threads (not including active scheduler, if any). Deafault FF_AUTO = N. of HW contexts. |
| spinwait | barrier kind. true nonblocking, false blocking. Nonbloking barrier will leave worker threads active until class destruction is called (the threads will be active and in the nonblocking barrier only after the first call to one of the parallel_for methods). To put threads to sleep between different calls, the threadPause method may be called. |
|
inline |
Destructor.
Terminate ParallelFor run-time support and makes resources housekeeping. Both nonlocking and blocking worker threads are terminated.
|
inline |
Disable active scheduler (i.e. Emitter thread)
Disable active scheduler (i.e. Emitter thread of the master-worker implementation). Active scheduling uses one dedicated nonblocking thread. In passive scheduling, workers cooperatively schedule tasks via synchronisations in memory. None of the above is always faster than the other: it depends on parallelism degree, task grain and platform. As rule of thumb on large multicore and fine-grain tasks active scheduling is faster. On few cores passive scheduler enhances overall performance. Active scheduler is the default option.
| onoff | true disable active schduling, false enable active scheduling |
|
inline |
Parallel for region (basic) - static.
Static scheduling onto nw worker threads. Data is statically partitioned in blocks, i.e. partition size = last-first/(nw*step).
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| f | f(const long idx) Lambda function, body of the parallel loop. idx: iterator |
| nw | number of worker threads (default FF_AUTO) |
|
inline |
Parallel for region (step) - static.
Static scheduling onto nw worker threads. Iteration space is walked with stride step. Data is statically partitioned in blocks, i.e. partition size = last-first/(nw*step).
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| f | f(const long idx) body of the parallel loop |
| nw | number of worker threads |
|
inline |
Parallel for region (step, grain) - dynamic.
Dynamic scheduling onto nw worker threads. Iterations are scheduled in blocks of minimal size grain. Iteration space is walked with stride step.
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| grain | (> 0) minimum computation grain (n. of iterations scheduled together to a single worker) |
| f | f(const long idx) Lambda function, body of the parallel loop. idx: iteration param nw number of worker threads |
|
inline |
Parallel for region with indexes ranges (step, grain, thid, idx) - dynamic - advanced usage.
Dynamic scheduling onto nw worker threads. Iterations are scheduled in blocks of minimal size grain. Iteration space is walked with stride step. A chunk of grain iterations are assigned to each worker but they are not automatically walked. Each chunk can be traversed within the parallel_for body (e.g. with a for loop within f with the same step).
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| grain | (> 0) minimum computation grain (n. of iterations scheduled together to a single worker) |
| f | f(const long start_idx, const long stop_idx, const int thid) Lambda function, body of the parallel loop. start_idx and stop_idx: iteration bounds assigned to worker_id thid. |
| nw | number of worker threads (default n. of platform HW contexts) |
|
inline |
Parallel for region (step, grain) - static.
Static scheduling onto nw worker threads. Iterations are scheduled in blocks of minimal size grain > 1 or in maximal partitions grain == 0. Iteration space is walked with stride step.
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| grain | (> 0) minimum computation grain (n. of iterations scheduled together to a single worker) |
| f | f(const long idx) Lambda function, body of the parallel loop. start_idx and stop_idx: iteration bounds assigned to worker_id thid. |
| nw | number of worker threads (default n. of platform HW contexts) |
|
inline |
Parallel for region with threadID (step, grain, thid) - dynamic.
Dynamic scheduling onto nw worker threads. Iterations are scheduled in blocks of minimal size grain. Iteration space is walked with stride step. thid Worker thread ID is made available via a Lambda parameter.
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| grain | minimum computation grain (n. of iterations scheduled together to a single worker) |
| f | f(const long idx, const int thid) Lambda function, body of the parallel loop. idx: iteration, thid: worker_id |
| nw | number of worker threads (default n. of platform HW contexts) |
| class ff::ParallelForReduce |
Parallel for and reduce. Run automatically.
Set up the run-time for parallel for and parallel reduce.
Parallel for: Identifies an iterative work-sharing construct that specifies a region (i.e. a Lambda function) in which the iterations of the associated loop should be executed in parallel. in parallel.
Parallel reduce: reduce an array of T to a single value by way of an associative operation.
| T | reduction op type: op(T,T) -> T |
Inherited by ff::ff_Map< T >, and ff::ff_Map<>.
Public Member Functions | |
| ParallelForReduce (const long maxnw=FF_AUTO, bool spinwait=false) | |
| Constructor. More... | |
| template<typename Function > | |
| void | parallel_for (long first, long last, const Function &f, const long nw=FF_AUTO) |
| Parallel for region (basic) - static. More... | |
| template<typename Function > | |
| void | parallel_for (long first, long last, long step, const Function &f, const long nw=FF_AUTO) |
| Parallel for region (step) - static. More... | |
| template<typename Function > | |
| void | parallel_for (long first, long last, long step, long grain, const Function &f, const long nw=FF_AUTO) |
| Parallel for region (step, grain) - dynamic. More... | |
| template<typename Function > | |
| void | parallel_for_thid (long first, long last, long step, long grain, const Function &f, const long nw=FF_AUTO) |
| Parallel for region with threadID (step, grain, thid) - dynamic. More... | |
| template<typename Function > | |
| void | parallel_for_idx (long first, long last, long step, long grain, const Function &f, const long nw=FF_AUTO) |
| Parallel for region with indexes ranges (step, grain, thid, idx) - dynamic - advanced usage. More... | |
| template<typename Function > | |
| void | parallel_for_static (long first, long last, long step, long grain, const Function &f, const long nw=FF_AUTO) |
| Parallel for region (step) - static. More... | |
| template<typename Function , typename FReduction > | |
| void | parallel_reduce (T &var, const T &identity, long first, long last, const Function &partialreduce_body, const FReduction &finalreduce_body, const long nw=FF_AUTO) |
| Parallel reduce (basic) More... | |
| template<typename Function , typename FReduction > | |
| void | parallel_reduce (T &var, const T &identity, long first, long last, long step, const Function &body, const FReduction &finalreduce, const long nw=FF_AUTO) |
| Parallel reduce (step) More... | |
| template<typename Function , typename FReduction > | |
| void | parallel_reduce (T &var, const T &identity, long first, long last, long step, long grain, const Function &body, const FReduction &finalreduce, const long nw=FF_AUTO) |
| Parallel reduce (step, grain) More... | |
| template<typename Function , typename FReduction > | |
| void | parallel_reduce_static (T &var, const T &identity, long first, long last, long step, long grain, const Function &body, const FReduction &finalreduce, const long nw=FF_AUTO) |
| Parallel reduce region (step) - static. More... | |
Protected Member Functions | |
| ParallelForReduce (const long maxnw, bool spinWait, bool skipWarmup) | |
| Constructor. More... | |
|
inlineprotected |
Constructor.
| maxnw | Maximum number of worker threads |
| spinWait | true Noblocking support (run-time thread will never suspend, even between successive calls to parallel_for and parallel_reduce, useful when they are called in sequence on small kernels), false blocking support |
| skipWarmup | Skip warmup phase (autotuning) |
|
inline |
Constructor.
| maxnw | Maximum number of worker threads |
| spinwait | true for noblocking support (run-time thread will never suspend, even between successive calls to parallel_for and parallel_reduce, useful when they are called in sequence on small kernels), false blocking support |
|
inline |
Parallel for region (basic) - static.
Static scheduling onto nw worker threads. Data is statically partitioned in blocks, i.e. partition size = last-first/(nw*step).
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| f | f(const long idx) Lambda function, body of the parallel loop. idx: iterator |
| nw | number of worker threads (default FF_AUTO) |
|
inline |
Parallel for region (step) - static.
Static scheduling onto nw worker threads. Data is statically partitioned in blocks, i.e. partition size = last-first/(nw*step).
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| f | f(const long idx) body of the parallel loop |
| nw | number of worker threads |
|
inline |
Parallel for region (step, grain) - dynamic.
Dynamic scheduling onto nw worker threads. Iterations are scheduled in blocks of minimal size grain. Iteration space is walked with stride step.
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| grain | (> 0) minimum computation grain (n. of iterations scheduled together to a single worker) |
| f | f(const long idx) Lambda function, body of the parallel loop. idx: iteration param nw number of worker threads |
|
inline |
Parallel for region with indexes ranges (step, grain, thid, idx) - dynamic - advanced usage.
Dynamic scheduling onto nw worker threads. Iterations are scheduled in blocks of minimal size grain. Iteration space is walked with stride step. A block of grain iterations are assigned to each worker but they are not automatically walked. Each block can be traversed within the parallel_for body (e.g. with a for loop within f with the same step).
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| grain | (> 0) minimum computation grain (n. of iterations scheduled together to a single worker) |
| f | f(const long start_idx, const long stop_idx, const int thid) Lambda function, body of the parallel loop. start_idx and stop_idx: iteration bounds assigned to worker_id thid. |
| nw | number of worker threads (default n. of platform HW contexts) |
|
inline |
Parallel for region (step) - static.
Static scheduling onto nw worker threads. Iteration space is walked with stride step. Data is statically partitioned in blocks, i.e. partition size = last-first/(nw*step)
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| f | f(const long idx) body of the parallel loop |
| nw | number of worker threads |
|
inline |
Parallel for region with threadID (step, grain, thid) - dynamic.
Dynamic scheduling onto nw worker threads. Iterations are scheduled in blocks of minimal size grain. Iteration space is walked with stride step. thid Worker thread ID is made available via a Lambda parameter.
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| grain | minimum computation grain (n. of iterations scheduled together to a single worker) |
| f | f(const long idx, const int thid) Lambda function, body of the parallel loop. idx: iteration, thid: worker_id |
| nw | number of worker threads (default n. of platform HW contexts) |
|
inline |
Parallel reduce (basic)
Data is statically partitioned in blocks, i.e. partition size = last-first/(nw*step)
Reduce is executed in two phases: the first phase execute in parallel a partial reduce (by way of partialreduce_body function), the second reduces partial results (by way of finalresult_body). Typically the two function are really the same.
| var | inital value of reduction variable (accumulator) |
| indentity | indetity value for the reduction function |
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| partialreduce_body | reduce operation (1st phase, executed in parallel) |
| finalreduce_body | reduce operation (2nd phase, executed sequentially) |
| nw | number of worker threads |
|
inline |
Parallel reduce (step)
Iteration space is walked with stride step. Data is statically partitioned in blocks, i.e. partition size = last-first/(nw*step)
Reduce is executed in two phases: the first phase execute in parallel a partial reduce (by way of partialreduce_body function), the second reduces partial results (by way of finalresult_body). Typically the two function are really the same.
| var | inital value of reduction variable (accumulator) |
| indentity | indetity value for the reduction function |
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| partialreduce_body | reduce operation (1st phase, executed in parallel) |
| finalreduce_body | reduce operation (2nd phase, executed sequentially) |
| nw | number of worker threads |
|
inline |
Parallel reduce (step, grain)
Dynamic scheduling onto nw worker threads. Iterations are scheduled in blocks of minimal size grain. Iteration space is walked with stride /p step.
Reduce is executed in two phases: the first phase execute in parallel a partial reduce (by way of partialreduce_body function), the second reduces partial results (by way of finalresult_body). Typically the two function are really the same.
| var | inital value of reduction variable (accumulator) |
| indentity | indetity value for the reduction function |
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| partialreduce_body | reduce operation (1st phase, executed in parallel) |
| finalreduce_body | reduce operation (2nd phase, executed sequentially) |
| nw | number of worker threads |
|
inline |
Parallel reduce region (step) - static.
Static scheduling onto nw worker threads. Iteration space is walked with stride step. Data is statically partitioned in blocks, i.e. partition size = last-first/(nw*step)
| var | inital value of reduction variable (accumulator) |
| indentity | indetity value for the reduction function |
| first | first value of the iteration variable |
| last | last value of the iteration variable |
| step | step increment for the iteration variable |
| f | f(const long idx) body of the parallel loop |
| nw | number of worker threads |
| class ff::ff_pipe |
Pipeline pattern (high-level pattern syntax)
Set up a parallel for pipeline pattern run-time support object. Run with run_and_wait_end or run_the_freeze. See related functions.
Inheritance diagram for ff::ff_pipe< TaskType >: Collaboration diagram for ff::ff_pipe< TaskType >:Public Member Functions | |
| template<typename... Arguments> | |
| ff_pipe (Arguments...args) | |
Create a stand-alone pipeline (no input/output streams). Run with run_and_wait_end or run_the_freeze. More... | |
| template<typename... Arguments> | |
| ff_pipe (bool input_ch, Arguments...args) | |
Create a pipeline (with input stream). Run with run_and_wait_end or run_the_freeze. More... | |
| Public Member Functions inherited from ff::ff_pipeline | |
| ff_pipeline (bool input_ch=false, int in_buffer_entries=DEF_IN_BUFF_ENTRIES, int out_buffer_entries=DEF_OUT_BUFF_ENTRIES, bool fixedsize=true) | |
| Constructor. More... | |
| ~ff_pipeline () | |
| Destructor. | |
| int | add_stage (ff_node *s) |
| It adds a stage to the pipeline. More... | |
| int | wrap_around (bool multi_input=false) |
| Feedback channel (pattern modifier) More... | |
| int | run (bool skip_init=false) |
| Run the pipeline skeleton asynchronously. More... | |
| int | wait () |
| wait for pipeline termination (all stages received EOS) | |
| int | wait_freezing () |
| wait for pipeline to complete and suspend (all stages received EOS) More... | |
| bool | offload (void *task, unsigned int retry=((unsigned int)-1), unsigned int ticks=ff_node::TICKS2WAIT) |
| offload a task to the pipeline from the offloading thread (accelerator mode) More... | |
| bool | load_result (void **task, unsigned int retry=((unsigned int)-1), unsigned int ticks=ff_node::TICKS2WAIT) |
| gets a result from a task to the pipeline from the main thread (accelator mode) More... | |
| bool | load_result_nb (void **task) |
| try to get a result from a task to the pipeline from the main thread (accelator mode) More... | |
| double | ffTime () |
| Misure ff::ff_node execution time. More... | |
| Public Member Functions inherited from ff::ff_node | |
| virtual bool | put (void *ptr) |
| Nonblocking put onto output channel. More... | |
| virtual bool | get (void **ptr) |
| Noblocking pop from input channel. More... | |
| virtual FFBUFFER * | get_in_buffer () const |
| Gets input channel. More... | |
| virtual FFBUFFER * | get_out_buffer () const |
| Gets pointer to the output channel. More... | |
| virtual bool | ff_send_out (void *task, unsigned int retry=((unsigned int)-1), unsigned int ticks=(TICKS2WAIT)) |
| Sends out the task. More... | |
Additional Inherited Members | |
| Protected Member Functions inherited from ff::ff_pipeline | |
| void * | svc (void *task) |
| The service callback (should be filled by user with parallel activity business code) More... | |
| int | svc_init () |
| Service initialisation. More... | |
| void | svc_end () |
| Service finalisation. More... | |
| int | create_input_buffer (int nentries, bool fixedsize) |
| Creates the input channel. More... | |
| int | create_output_buffer (int nentries, bool fixedsize=false) |
| Creates the output channel. More... | |
| int | set_output_buffer (FFBUFFER *const o) |
| Assign the output channelname to a channel. More... | |
| Protected Member Functions inherited from ff::ff_node | |
| virtual void | skipfirstpop (bool sk) |
| Set the ff_node to start with no input task. More... | |
| bool | skipfirstpop () const |
| Gets the status of spontaneous start. More... | |
| virtual int | set_input_buffer (FFBUFFER *const i) |
| Assign the input channelname to a channel. More... | |
| virtual double | wffTime () |
| Misure ff_node::svc execution time. More... | |
| virtual | ~ff_node () |
| Destructor. | |
| Related Functions inherited from ff::ff_pipeline | |
| int | run_and_wait_end () |
| run the pipeline, waits that all stages received the End-Of-Stream (EOS), and destroy the pipeline run-time More... | |
| virtual int | run_then_freeze (bool skip_init=false) |
| run the pipeline, waits that all stages received the End-Of-Stream (EOS), and suspend the pipeline run-time More... | |
|
inline |
Create a stand-alone pipeline (no input/output streams). Run with run_and_wait_end or run_the_freeze.
Identifies an stream parallel construct in which stages are executed in parallel. It does require a stream of tasks, either external of created by the first stage.
| args | pipeline stages, i.e. a list f1,f2,... of functions with the following type const std::function<T*(T*,ff_node*const)> |
Example: pipe_basic.cpp
|
inline |
Create a pipeline (with input stream). Run with run_and_wait_end or run_the_freeze.
Identifies an stream parallel construct in which stages are executed in parallel. It does require a stream of tasks, either external of created by the first stage.
| input_ch | true to enable first stage input stream |
| args | pipeline stages, i.e. a list f1,f2,... of functions with the following type const std::function<T*(T*,ff_node*const)> |
Example: pipe_basic.cpp
| class ff::poolEvolution |
The pool evolution parallel pattern.
The pool pattern computes the set P as result of the following algorithm:
while not( t(P) ) do N = e ( s(P) ) P += f (N, P) end while
where 's' is a “candidate selection” function, which selects a subset of objects belonging to an unstructured object pool (P), 'e' is the "evolution" function, 'f' a "filter" function and 't' a "termination" function.
Inheritance diagram for ff::poolEvolution< T, env_t >: Collaboration diagram for ff::poolEvolution< T, env_t >:Protected Member Functions | |
| void * | svc (void *task) |
| The service callback (should be filled by user with parallel activity business code) More... | |
| Protected Member Functions inherited from ff::ff_node | |
| virtual void | skipfirstpop (bool sk) |
| Set the ff_node to start with no input task. More... | |
| bool | skipfirstpop () const |
| Gets the status of spontaneous start. More... | |
| virtual int | create_input_buffer (int nentries, bool fixedsize=true) |
| Creates the input channel. More... | |
| virtual int | create_output_buffer (int nentries, bool fixedsize=false) |
| Creates the output channel. More... | |
| virtual int | set_output_buffer (FFBUFFER *const o) |
| Assign the output channelname to a channel. More... | |
| virtual int | set_input_buffer (FFBUFFER *const i) |
| Assign the input channelname to a channel. More... | |
| virtual int | run (bool=false) |
| Run the ff_node. More... | |
| virtual int | wait () |
| Wait ff_node termination. More... | |
| virtual int | wait_freezing () |
| Wait the freezing state. More... | |
| virtual double | ffTime () |
| Misure ff::ff_node execution time. More... | |
| virtual double | wffTime () |
| Misure ff_node::svc execution time. More... | |
| virtual | ~ff_node () |
| Destructor. | |
Additional Inherited Members | |
| Public Member Functions inherited from ff::ff_node | |
| virtual int | svc_init () |
| Service initialisation. More... | |
| virtual void | svc_end () |
| Service finalisation. More... | |
| virtual bool | put (void *ptr) |
| Nonblocking put onto output channel. More... | |
| virtual bool | get (void **ptr) |
| Noblocking pop from input channel. More... | |
| virtual FFBUFFER * | get_in_buffer () const |
| Gets input channel. More... | |
| virtual FFBUFFER * | get_out_buffer () const |
| Gets pointer to the output channel. More... | |
| virtual bool | ff_send_out (void *task, unsigned int retry=((unsigned int)-1), unsigned int ticks=(TICKS2WAIT)) |
| Sends out the task. More... | |
|
inlineprotectedvirtual |
The service callback (should be filled by user with parallel activity business code)
| task | is a the input data stream item pointer (task) |
Implements ff::ff_node.
 1.8.7
1.8.7